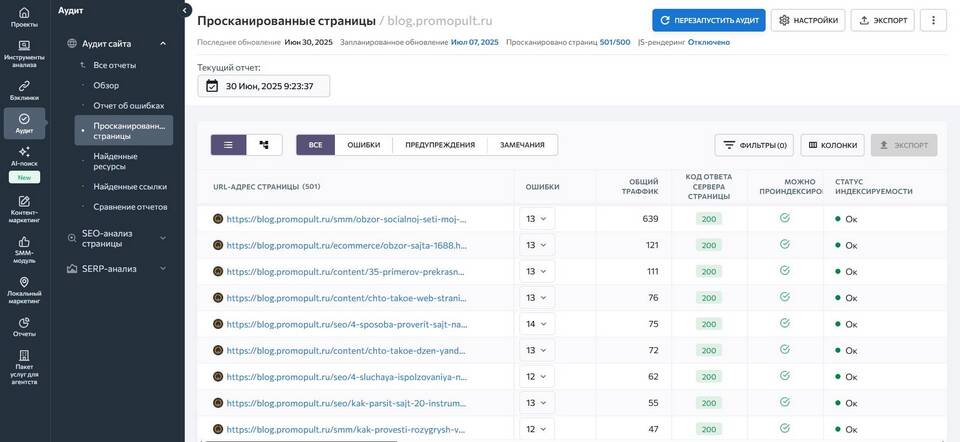
Парсинг данных с Яндекс Маркета позволяет собирать актуальную информацию о товарах, ценах и отзывах для анализа рынка. Рассмотрим основные методы сбора данных с использованием Python.
Содержание
Необходимые инструменты
- Python 3.7 или новее
- Библиотеки requests, BeautifulSoup4, lxml
- Прокси-серверы для обхода блокировок
- User-Agent ротация
Основные подходы к парсингу
| Метод | Преимущества | Недостатки |
| Парсинг HTML | Простота реализации | Хрупкость к изменениям верстки |
| Использование API | Стабильность работы | Ограничения API |
| Selenium | Работа с JavaScript | Низкая скорость |
Пример кода для парсинга HTML
Установка зависимостей
- pip install requests beautifulsoup4 lxml
- pip install fake-useragent
Базовый парсер карточек товаров
- Получение HTML страницы категории
- Извлечение данных с помощью CSS-селекторов
- Сохранение результатов в CSV или JSON
Обработка пагинации
- Определение общего количества страниц
- Последовательный обход всех страниц
- Обработка ограничений (задержки между запросами)
Обход защиты от парсинга
| Метод | Реализация |
| User-Agent ротация | Использование fake-useragent |
| Прокси | Чередование IP-адресов |
| Задержки | random.sleep между запросами |
Этические и юридические аспекты
- Проверка robots.txt Яндекс Маркета
- Соблюдение условий использования сервиса
- Ограничение частоты запросов
- Использование данных только в личных целях
Альтернативные методы сбора данных
- Официальное API Яндекс Маркета
- Готовые решения для парсинга
- Сервисы сбора данных по подписке
При парсинге важно соблюдать баланс между эффективностью сбора данных и нагрузкой на серверы Яндекс Маркета, чтобы избежать блокировки.